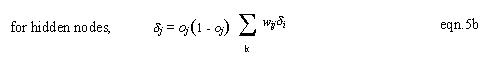|
where, ti = target output at output node i
During the backpropagation phase careful attention must be paid to the settings of the learning rate and momentum term. The learning rate must be high enough for the network to successfully converge, but low enough that the error function does not hit a local minimum and cease training to early. The momentum term if set correctly reduces the chances of local minima trappings.
If too many epochs of backpropagation are performed during training, there is a risk of overfitting occurring. This is where the network 'overtrains' and thus loses its ability to generalise in its classification of input patterns. This scenario can be avoided if some of the following steps are used:-
- During training, backpropagation is only performed on training patterns that can not be correctly classified by the network, this is in order that the network does not continuously train on patterns it can already recognise
- A realistic value for the acceptable training error is decided on. When the network reaches this value training ceases
- Gaussian noise is introduced at the inputs of the network during training, meaning that each time a pattern is presented to the network it will be slightly different
For the purposes of this project we will limit ourselves to using combination of the first two methods.
|
|