|
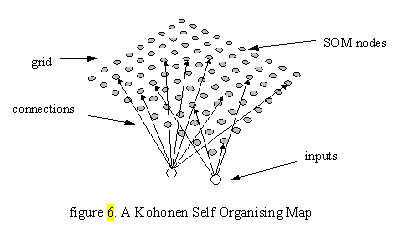
What the SOM aims to do is to group together training patterns exhibiting similar traits into 'clusters'. These clusters, represented by groups of nodes in the map, can then be labelled by the user and used to identify further patterns. |
||
|
During each epoch of the training cycle, all patterns of the training set are presented to the map. A winning node is chosen for each pattern, and is decided as the node whose weight vector most closely matches that of the input vector. This node can be found using the following equation (Kohonen 1998): |
||

|
where xi(t) is the ith input at time t |
||
|
where wj is the weight vector of node j at time t |
||

|
here, h0 is the initial learning rate. The time constant t1 controls the rate at which h falls. |
||