|
This process is repeated until the output layer has been reached. The combination of the forwardProp() and calcSigmoid functions constitute equations 3a and 3b.
If the network is recurrent (as specified by #define RECURRENT in the header file Drum.h, appendix C1) the function Node: :recurrentFowardProp() is called for the nodes of the first hidden layer. This is in order that he previous outputs for this layer for each time segment can be stored.
5.3.1.3. Backpropagation
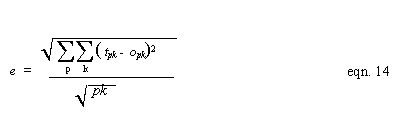
This takes place in the MLP member function trainNet(), which takes as its argument a pointer to an array holding all the TraingingVects structs (see section 5.2.1). Before backpropagation can occur for a pattern in the training set, a forward pass must be performed for that pattern. The backpropagation algorithms for the feed forward and recurrent networks differ and are described in the subsequent sections. In order that training error graphs can be created for each training session, trainNet() opens up a text file that records the error measured for each epoch. The error is calculated using the following equation:
|
|