|
6. Analysis of Results
6.1. Multi-Layer Perceptrons
Please refer to section 5.3.1.3 for an explanation of how the error is calculated.
6.1.1. Error vs epoch observations
6.1.1.1. Adjusting learning rate and momentum term
In order to successfully train each of the different type of MLP structure, it was important to look at how the learning rate and momentum term affected error during training. A cross section of MLP structures were observed. Figure 11 shows a specific example in the case of training a 30:35:5 network with the noisy data set (see section 3.2.4). It can be seen here and also in the majority of other networks that the combination of a learning rate of 0.5 and a momentum term of 0.3 yield an error curve that descends at a comparatively fast rate with little fluctuation (see section 3.4.1 for term explanations). The absence of fluctuation in error graphs indicates that the network has less chance of getting caught in local minima (see section 3.4.1), however the learning rate should not be made too small to avoid unsuccessful convergence. In the case of more complex structures, such as those with 2 hidden layers, and also the recurrent networks, these values seem to work best at around 0.2 and 0.1 respectively (figure 12c).
For the training sessions of subsequent networks it was thus decided to choose appropriate values of learning rate and momentum taken from these results.
Comparing figure 11c with figure 12b confirms that introducing noise to the training pattern of an MLP helps to minimise training error (noisy 3.8%, clean 4.8%). It will be observed later that this also reduces classification error, so from now on we will focus on networks trained with noisy data..
An interesting side observation here is that the 30:5 network (no hidden layer; figure 12a) cannot train to an error of less than 22.6%. This suggests a degree of linear inseparability inherent in the types of pattern in question.
It is noticeable in all the above cases that the training error does not get any lower than approximately 4%. This is not the case in networks of a higher number of hidden nodes or networks of two hidden layers (figure 13 a and b). This can be explained by the following:
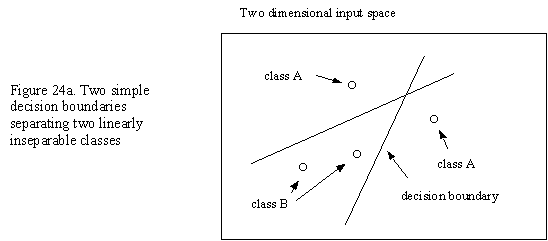
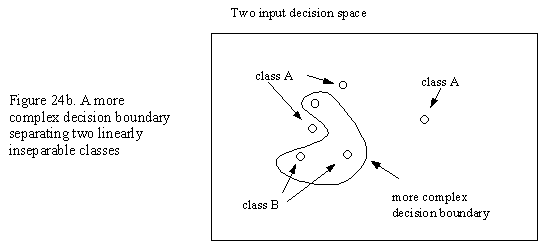
For a simple network of two inputs, the classification capability can regarded as dividing up areas in the 2-dimensional input space. Adding a hidden layer gives the ability to detect linearly inseparable patterns (by adding an additional decision boundary). Increasing the number of hidden nodes or hidden layers further increases the complexity of these classification areas and thus the ability of the network to learn an evermore complex training set (see figures 24a and 24b below).
|
|